Publicado: mié, 30/10/2024
| Actualizado: mié, 7/1/2026
Este post, además de servir como introducción a esta serie, es también la hoja de ruta principal de este blog en lo que a Data Engineering se refiere.
Todos los posts relacionados que vaya subiendo a futuro serán añadidos a esta sección, de modo que siempre puedas venir a este índice para encontrar el resto.
Pro tip: guardate este post en tus marcadores y pasate cada tanto para ver qué hay de nuevo.
SERIE DATA ENGINEERING - ÍNDICE
En mayo de 2024, unos meses después de haber comenzado mi primera experiencia laboral IT, decidí reorientar mi camino profesional hacia una rama muy interesante, relativamente “joven” y que se encuentra en demanda creciente: Data Engineering.
Donde me encuentro trabajando actualmente realizo integraciones de datos y procesos ETL. No voy a ahondar (todavía) en qué es un ETL, pero básicamente es tomar datos desde una fuente y transformarlos en algo distinto para que luego estos datos solucionen las necesidades de quien consuma dichos datos. Cuando apenas comencé a trabajar todo esto me resultaba muy novedoso: no tenía idea de qué era un ETL y para mi el concepto de “Data” se reducía a estructuras de datos. Es más, no tenía ni idea de la diferencia entre los distintos roles en data. Solo asumía que era un rubro muy difícil y poco interesante ya que había que pasársela haciendo gráficos (sí, así de ignorante era).
A medida que pasaron los meses empecé a participar de más proyectos donde el patrón se repetía: hay una fuente de datos (un Excel, una base de datos, una API, etc), y hay alguien que necesita que esos datos cambien, que resuelvan una necesidad en base a ciertas reglas de negocio y que esos datos “fluyan” con cierta frecuencia. Así, sin darme cuenta, ya estaba encargándome de una “patita” de lo que se conoce como Ingenieria de Datos.
Antes de comenzar en este puesto laboral yo ya tenía conocimientos de backend en general, de Python y también tenía nociones sobre bases de datos. Data Engineering se solapa con esta área del desarrollo, por lo que si bien dar mis primeros pasos tuvo su cuota de fricción, me sorprendió lo bien que me terminé adaptando en relativamente poco tiempo. Hoy no me considero un experto en estos conocimientos, pero he avanzado bastante.
Fiel a mi forma de ser, no me bastaba con cumplir con los proyectos y listo. Quería saber más, quería entender mejor el proceso que hago a diario para poder refinarlo y perfeccionarlo. Muchas cosas en la vida se relacionan con modelos mentales, y, en mi caso, quería y quiero tener el modelo mental de un Ingeniero de datos. Puse manos a la obra, busqué recursos, me anoté en Datacamp y comencé a indagar.
Este post es el resultado de estos meses de estudio sobre el tema y es el primero de varios que espero publicar en el tiempo sobre Data Engineering. No solo me sirve de repaso para estudiar, sino que también quiero que vos, que estás leyendo estas líneas, sepas qué es y qué NO es Data Engineering. En una de esas te convierto al lado oscuro (? o quizá pueda contribuir con mi granito de arena a que tomes una decisión si es que estás evaluando un cambio profesional. Comencemos.
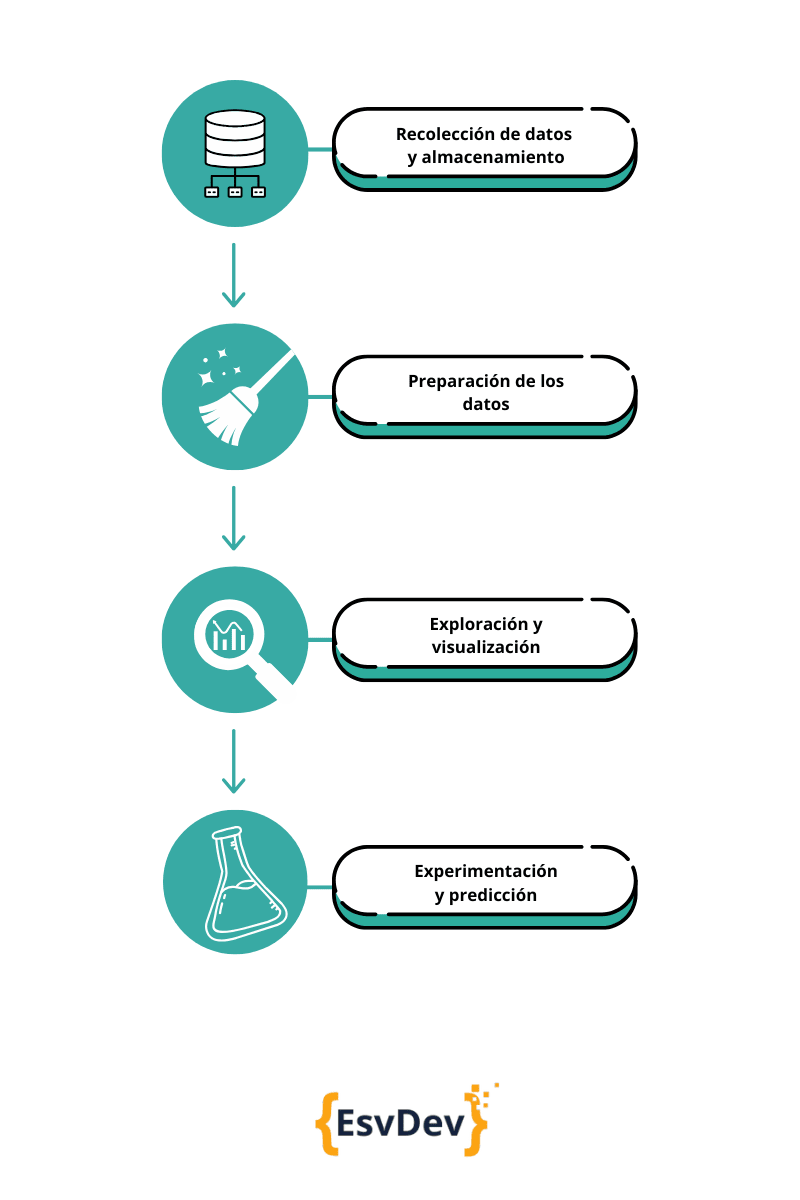
Para comprender de qué se trata este campo dentro del ecosistema de Data, primero tenemos que hablar del ciclo de vida de los datos. Existen cuatro pasos generales por los cuales los datos fluyen en una organización.
Data Engineering, y quien la ejerce, el/la Data Engineer, se encargan del primer paso de este ciclo.
👉🏻 Según el libro Fundamentals of Data Engineering de Joe Reis & Matt Housley, esta es la definición de lo que es Data Engineering:
”Data Engineering es el desarrollo, implementación y mantenimiento de sistemas y procesos que reciben data en formato ‘crudo’ y producen información consistente y de alta calidad que satisface casos de uso posteriores como el análisis o machine learning.
Un Data Engineer gestiona el ciclo de vida de la Ingenieria de Datos, comenzando con obtener datos de sistemas fuente y finaliza con servir estos datos para los casos de uso correspondientes.
Este profesional suele actuar como un puente entre productores de datos, como Ingenieros de Software, Arquitectos de Datos y SREs, y consumidores de datos, tales como Analistas de Datos, Científicos de Datos e Ingenieros de Machine Learning”.
Como dijimos, los Ingenieros de Datos son responsables del primer paso del proceso descrito anteriormente: ingerir y almacenar datos. Estos profesionales tienen una gran responsabilidad ya que establecen los fundamentos sobre los cuales los Analistas de Datos, Científicos de Datos e Ingenieros de Machine Learning realizan su trabajo. Si los datos se hallan dispersos o desorganizados, corrompidos o no es fácil acceder a ellos, no hay mucho que preparar, explorar y por lo tanto, no hay mucho (o nada) con lo que experimentar adecuadamente.
Un Ingeniero de Datos se encarga de entregar:
Entre sus distintas responsabilidades se encuentran:
🙅♂️ ¿Qué cosas no hace un Ingeniero de Datos? Típicamente este/a profesional no construye modelos de Machine Learning de manera directa, no crea reportes ni visualizaciones o dashboards. Tampoco realiza análisis sobre los datos, no construye indicadores claves de performance (KPI) ni desarrolla aplicaciones de software. Sin embargo, un Ingeniero de Datos debería tener una comprensión funcional de dichas áreas para ser lo más efectivo posible.
El último punto dentro de las responsabilidades que tiene un Data Engineer habla sobre “gestionar enormes cantidades de datos”. Cuando hablamos de cantidades enormes de información, no hablamos de otra cosa que Big Data. Existen conjuntos de datos tan grandes, que es obligatorio pensar cómo lidiar con su tamaño, ya que es difícil o incluso imposible procesar estos datos utilizando los métodos tradicionales de gestión de datos.
Ordenado por volumen, este tipo de data se compone de:
Es importante que la Ingeniera de Datos tenga en cuenta los siguientes factores al momento de lidiar con Big Data. Estos factores son conocidos como “las 5 V”:
🤔 De acuerdo con los autores de Fundamentals of Data Engineering, el término Big Data es una reliquia que describe una época particular y una manera de gestionar grandes cantidades de datos:
“Hoy, los datos se mueven más rápido que nunca y crecen aún más, pero el procesamiento de grandes cantidades de datos se ha vuelto tan accesible que ya no amerita un término aparte; cada compañía apunta a resolver sus problemas de datos, independientemente del tamaño de estos. Los Ingenieros de Big Data, ahora simplemente son Ingenieros de Datos".
Ahora que sabemos básicamente qué es lo que hace un/a Data Engineer, hablemos sobre los conocimientos técnicos que es importante adquirir para desempeñarse con éxito en este campo. Un Ingeniero de Datos debe entender y conocer las mejores prácticas en lo que se refiere a gestión de datos y tener una buena comprensión de lo que es Ingeniería de Software. Tal es así, que un Data Engineer que no sea capaz de escribir código de calidad para producción se encontrará severamente obstaculizado. Como dice el libro citado anteriormente, “los Ingenieros de Datos siguen siendo Ingenieros de Software, en adición a sus muchos otros roles”.
Dentro de los conocimientos técnicos indispensables, podemos destacar los siguientes:

Si bien estas competencias técnicas sirven para construir una base sólida en este campo, puede ser necesario familiarizarse con otros lenguajes como R, Go, Rust, C/C++ o incluso C# y Powershell si la compañia donde trabajemos se desempeña en un ecosistema de Microsoft o utilice Azure.
Ahora bien, existen ciertas habilidades que, junto a las técnicas, son importantes que desarrollemos para ser un Data Engineer competente, entre las que se pueden destacar:
Ahora que sabemos en líneas generales qué hace un Ingeniero de Datos y qué conocimientos necesita para desempeñarse eficientemente, resta preguntarnos dónde podemos obtener dichos conocimientos. Para la fecha de publicación de este post, no he encontrado ninguna oferta de educación formal orientada completamente a lo que es Data Engineering. Si bien existen carreras sobre Ciencia de Datos e Inteligencia Artificial, no he visto que los diferentes planes de estudio cubran a cabalidad todos los temas que se relacionan directamente con la posición en sí.
Sin embargo, existen muchos recursos (gratuitos y pagos) que nos permitirán adentrarnos en este campo. Te dejo algunos a continuación para que los consideres y, si crees que me falta algo, te invito a que me contactes así lo agrego a la lista.
La Ingeniería de Datos es la columna vertebral en el ecosistema de datos, responsable de transformar datos en bruto en información accesible y confiable para los equipos de Análisis, Ciencia de Datos y Machine Learning. Desde la ingesta y almacenamiento de datos hasta la creación de arquitecturas robustas y pipelines eficientes, los Ingenieros de Datos establecen la base para extraer valor de grandes volúmenes de información.
En la era de la Inteligencia Artificial y el Big Data, la importancia de la Ingeniería de Datos ha crecido exponencialmente. Las organizaciones de todos los sectores confían en estos profesionales para gestionar de forma eficaz enormes cantidades de datos y facilitar el acceso a información precisa, lo que permite tomar decisiones informadas y desarrollar modelos predictivos avanzados. Con la continua expansión de la IA y el aprendizaje automático, el rol de los Ingenieros de Datos seguirá siendo fundamental, impulsando la innovación y el desarrollo de tecnologías que transforman el mundo.
Ahora, decime: ¿estás listo/a para comenzar a aprender?

Data Engineer | Developer | Musico | Nerd de yerbas varias